Parametric UMAP
Posted on Sat 03 October 2020 in Machine Learning
Our new paper, "Parametric UMAP: learning embeddings with deep neural networks for representation and semi-supervised learning" (Sainburg, McInnes, Gentner, 2020) is posted on arXiv. In the paper, we propose a parametric variation of UMAP, which is normally a non-parametric algorithm.
The idea is simple: instead of optimizing UMAP over embeddings we optimize over a neural network.
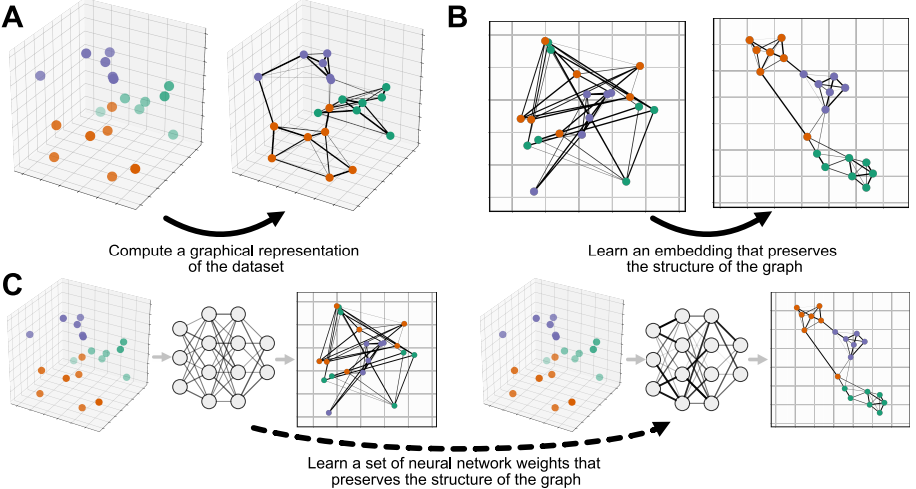
Overview of UMAP (A → B) and Parametric UMAP (A → C). See paper for more info.
In the paper, we explain how it was done, and why UMAP is so well suited to deep learning applications.
After exploring and characterizing Parametric UMAP's embeddings (speed, embeding quality, downstream tasks), we looked at how Parametric UMAP could be extended to novel deep learning applications like classification and autoencoding.

Extending Parametric UMAP. See paper for more info.
Here's a twitter thread going into some detail:
New paper "Parametric UMAP: learning embeddings with deep neural networks for representation and semi-supervised learning" with @leland_mcinnes and @TqGentner! 1/https://t.co/2x5YTZPSXU pic.twitter.com/WJ7ECE0DI4
— Tim Sainburg (@tim_sainburg) September 29, 2020
The code for then paper is available online and is added to v0.5 of UMAP.
Feel free to reach out if you have any questions!